
 Mongodb
Mongodb
# Mongodb
# 1.安装并启动Mongodb
下载安装包并傻瓜式安装
配置环境变量,将安装的mongodb路径添加在环境变量中去
在C盘(或D盘等)的根目录下创建一个
data文件夹,文件夹里面创建一个db文件夹(这是mongodb默认的路径)**注:**如果不想用默认路径可以自己选择一个空的文件夹创建
db文件打开命令行窗口输入
mongod启动mongdb服务器,默认在27017端口访问mongodb注:
如果只输入mongod就会使用默认的路径打开数据库,如果没有使用默认路径,需要使用
mongod --dbpath 自己设置的数据库db目录路径如果不想在27017端口访问mongodb,可以在最后的路径后面输入空格再加上
--port 端口号
重新打开一个cmd窗口(前面那个不要关闭 ),输入
mongo链接mongodb,出现>证明就能运行了
数据库(database)
- 数据库的服务器
- 服务器用来保存数据
mongod命令用于启动服务器
- 数据库的客户端
- 客户端用来操作服务器,对数据进行增删查改的操作
mongo用来启动客户端
# 2.Mongodb系统服务
将mongodb设置为系统服务,可以在后台启动,不需要每次都要手动启动
在C盘根目录下创建的data文件夹中创建db和log文件夹
创建配置文件,在下载的mongdb目录中(与bin文件夹在同一层级),添加一个配置文件mongod.cfg,内容如下:
systemLog: destination: file path: c:\data\log\mongod.log storage: dbPath: c:\data\db1
2
3
4
5**注意:**path路径必须是要和前面的操作相对应
然后以管理员身份打开cmd窗口,输入
C:\mongodb安装目录\bin\mongo.exe --config "C:\mongodb安装目录\mongod.cfg" --install例子:
C:\mongodb\bin\mongod.exe --config "C:\mongodb\mongod.cfg" --install输入
net start MongoDB启动mongodb服务(如果不生效,也可以打开任务管理器,找到相关服务,手动打开)
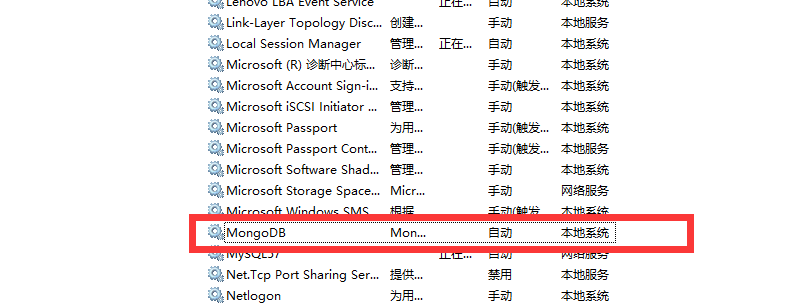
相关操作
net stop MongoDB关闭服务sc.exe delete MongoDB删除服务
# 3.基本概念
- 数据库(database)
- 集合(collection)
- 文档(document)
**注:**在mongodb中,数据库和集合都不需要手动创建,当我们创建文档时,如果文档所在的集合或数据库不存在会自动创建数据库和集合
# 3.1 导入导出数据
在mongodb中可以使用mongodump命令来备份mongodb数据。该命令可以导出所有数据到指定目录.可通过参数指定导出到数据量级转存的服务器
#mongodump -h dbhost(IP端口号) -d dbname(数据库名称) -o dbdiectory(存储备份数据的目录) mongodump -h 127.0.0.1 -d koa -o C:\Users\asus\Desktop\koaDb1
2在mongodb中可以使用mongorestore命令可以用来恢复备份的数据
#mongorestore -h dbhost -d dbname <path> mongorestore -h 127.0.0.1 -d koademo C:\Users\asus\Desktop\koaDb\koa #因为在上面导出数据库的时候是导出一整个数据库文件夹,所以需要进入到里面拿到koa文件夹1
2
3
# 4.指令
# 4.1 基本指令
show dbs和show databases——显示当前的所有数据库use 数据库名——进入到指定的数据库中db——表示当前所处的数据库show collections——显示数据库中所有的集合
# 4.2 CRUD(增删改查)指令
# 4.2.1 插入文档
db.<collection>.insert(),在insert()中接受一个对象或数组
db.test.insert({name:"张三",age:18});
db.test.insert([
{name:"张三",age:18},
{name"李四",age:19}
]);
2
3
4
5
6
**注意:**mongodb的属性值也可以是一个文档或一个数组,当一个文档的属性是文档时,我们说它是内嵌文档
# 4.2.2 查询文档
db.<collection>.find(),在find()可以接受一个对象作为条件参数,如果传入一个空对象就和不传一样会查找集合中所有的文档,{属性:值}查询指定属性对应值的文档db.test.find({name:"张三"});1注:
在开发时绝对不会执行不带条件的查询
find()的结果返回是一个数组,可以加上[0]等来查找指定的第几个文档
在后面可以加上
count()或length()可以返回一共查找到的文档数量db.test.find({name:"张三"}).count();1在后面可以加上
pretty()来格式化查询到的对象,便于观察结果在后面可以使用
limit()来限制显示文档的数量db.test.find({name:"张三"}).limit(10);//显示找到的从第一到第十条数据1在后面可以使用
skip()来跳过指定数量的数据,常和limit()配合使用db.test.find({name:"张三"}).skip(10).limit(10);//显示找到的从第十到第二十条数据1**注意:**按照常规的逻辑应该是先用
skip()再用limit(),但是如果两者交换了顺序mongodb也会进行自动的调整(如果在其中加入了sort()也会先执行sort()再执行其他两个)在后面加上
populate()可以进行查询关联,查询可以关联到其他的集合查询文档时,默认是按照
_id的值进行升序排列,如果需要按照自己指定的顺序进行查询的排列,需要用sort()来指定排序的规则,sort()需要传递一个对象来指定排序规则,1表示升序,-1表示降序**注:**可以在一个对象中传递多个排序规则,按照从左到右的规则进行排序,如果一样就按照下一个规则排序
db.test.find({name:"张三"}).sort({age:1}).skip(10).limit(10); db.test.find({name:"张三"}).sort({age:1,_id:-1}).skip(10).limit(10);1
2
3**mongodb支持直接通过内嵌文档的属性进行查询,**如果要查询内嵌文档则可以直接用
第一个文档的属性名.第二个文档的属性名的形式来匹配(类似于JS的对象嵌套),此时的属性名必须要带上引号如果要对查找的文档的属性进行大小等限制时,传入对象的属性值就为一个对象,该对象里面可以包含以下修饰操作符:
$gt(>),$gte(>=),$lt(<),$lte(<=),$ne(!=),$eq(==)**注:**这些关系表示符都可以在对象中写多个,进行多条件的限制查找
db.test.find({age:{$lt:25,$gt:18}});1$or在查询的时候可以表示或者的关系,放在最外层的对象属性中,其属性是一个数组db.test.find({$or:[{age:{$lt:18}},{age:{$gt:25}}]});//age大于25或小于181
在查询时,可以在
find()中传入第二个参数,在该参数位置设置查询结果的投影,设置了后就只会查询到的信息的指定结果,1代表显示该信息,0代表不显示db.test.find({name:"张三"},{age:1});//查询到的结果只会显示age和_id(默认的) db.test.find({name:"张三"},{age:1,_id:0});//查询结果只会显示age1
2
db.<collection>.findOne(),用来查询集合中符合条件的第一个文档,返回的是一个文档对象,所以可以直接.属性名查询到对应的属性值
# 4.2.3 修改文档
db.<collection>.update(查询条件,新对象)注意:
- update()默认会使用新对象替换旧对象,如果要修改指定的属性,而不是替换需要使用修改操作符
$set可以用来修改文档的指定属性$unset可以用来删除文档的指定属性$push可以向一个数组的文档属性中添加一个新的元素(可以添加相同的元素)$addToSet可以向一个数组的文档属性中添加一个新的元素(不可以添加相同的元素,如果匹配到了不会加到数组里面去)$inc可以将一个文档的指定属性值进行自增修改
db.test.update({name:"张三"},{$set:{ gender:"男"//只将gender属性加进去了,而其他两个属性依然还在 }}); db.test.update({name:"张三"},{$unset:{ name:1//因为是删除属性,所以后面的数据不管是什么都可以 }}) db.test.update({name:"张三"},{$inc:{ age:2;//年龄自增2,如果要减2则前面加-号 }})1
2
3
4
5
6
7
8
9
10
11- update()默认只会修改第一个符合条件的文档,如果想要修改多个文档,需要传入第三个对象参数,并在其中的
multi属性中写上true
- update()默认会使用新对象替换旧对象,如果要修改指定的属性,而不是替换需要使用修改操作符
db.<collection>.updateOne(查询条件,新对象),修改一个符合条件的文档db.<collection>.updateMany(查询条件,新对象),同时修改多个符合条件的文档
# 4.2.4 删除文档
db.<collection>.remove(),删除符合条件的所有的文档,如果不传入参数就会报错,如果传入的是一个空的对象,则会将所有的文档都删除**注意:**remove()默认情况下会删除所有复合条件的文档,如果只想删除第一个符合条件的文档,需要再给remove()传入第二个参数,该参数为一个布尔值,设置为true就为只删除第一个符合条件的文档
db.test.remove({name:"张三"}); db.test.remove({name:"张三",true}); db.test.remove({});//情况呢整个集合,但是性能较差 //如果真的想把一整个集合删除,使用下面的方式 db.test.drop();//该方法会直接将一个集合删除1
2
3
4
5
6
7db.<collection>.deleteOne(),删除集合中的第一个复合条件的文档db.<collection>.deleteMany(),删除集合中的所有复合条件的文档db.<collection>.drop(),删除集合db.dropDatabase,删除数据库
**注意:**一般数据库中的数据不会删除,所以删除的方法很少调用,一般会在数据库中添加一个字段来表示数据是否被删除
//如下面用isDel属性表示是否删除了某个文档
db.test.updateMany({},{isDel:0});
db.test.updateOne({name:"张三"},{$set:{
isDel:1
}});
db.test.find({isDel:0});
2
3
4
5
6
7
8
**注:**数据库的方法调用的时候尽量少调用,因为会非常的消耗性能,如果要连续插入很多的数据,最好先装在一个数组中再将整个数组传入到数据库中
//如同时向数据库中插入20000条数据
for(var i=0;i<20000;i++){
db.numbers.insert({num:i});//花费7.2s
}
var arr=[];
for(var i=1;i<20000;i++){
arr.push(i);
}
db.numbers.insert(arr);//花费0.4s
2
3
4
5
6
7
8
9
10
# 5.文档间的关系
一对一,通过内嵌文档的形式体现出一对一的关系
一对多/多对一,通过内嵌文档来映射一对多的关系(通过联表的文档查询)
var user_id=db.users.findOne({name:"张三"})._id;//在这获取到独立的_id db.order.insert({name:"苹果",user_id:user_id}); db.order.find({user_id:user_id});//通过两个文档的链接可以实现一对多的关系,通过_id进行查询1
2
3多对多,通过数组形式的内嵌文档来映射一对多的关系(通过联表的文档查询)
var user_id1=db.users.findOne({name:"张三"})._id; var user_id2=db.users.findOne({name:"李四"})._id; db.order.insert([{name:"苹果",user_id:[user_id1,user_id2]}]); db.order.find({name:"苹果"});1
2
3
4
# 6.Mongodb聚合管道
使用聚合管道可以对集合中的文档进行变换和组合
**具体用法:**使用aggregate()函数进行查询,内部传入一个数组作为参数,数组中是一个个聚合管道的对象,实现对应的功能
**实际项目:**表的关联查询、数据的统计
| 管道操作符 | 描述 |
|---|---|
| $project | 增加、删除、重命名字段 |
| $math | 条件匹配,只有满足条件的文档才能进入下一阶段 |
| $limit | 限制结果的数量 |
| $skip | 跳过文档的数量 |
| $sort | 条件排序 |
| $group | 条件组合结果 |
| $sum | 求和,计算选中的数量,通过赋值每满足一个文档就会增加相应的数量 |
| $lookup | 用于引入其它集合的数据 |
# 6.1 $project
修改文档的结构,可以用来重命名、增加或删除文档中的字段
db.test.aggregate([
{
$project:{trade_no:1,all_price:1}
//会查询出同时含有这两个属性的文档,同时查找出来的文档只会显示出这两个属性
}
])
2
3
4
5
6
# 6.2 $match
用于过滤文档,用法类似find()方法中的参数
db.test.aggregate([
{
$project:{trade_no:1,all_price:1}
},
{
$match:{"all_price":{$gte:90}}
//查找大于90价格的文档,该查询的初始数据是由上面的对象筛选下来的
}
])
2
3
4
5
6
7
8
9
# 6.3 $group
将集合中的文档进行分组,可用于统计结果
db.test.aggregate([
{
$ground:{_id:"$order_id",total:{$sum:"$num"}}
/*
将所有order_id相同的文档进行分组,分组后的一组属性的属性值有_id和total(都是自己设置),然 后用$sum聚合管道将所有组的num属性值加起来赋值给新的total属性
注意:这里面只依据了order_id进行分组,total不是用来分组的
*/
}
])
2
3
4
5
6
7
8
9
# 6.4 $sort
将集合中的文档进行排序
db.test.aggregate([
{
$project:{trade_no:1,all_price:1}
},
{
$match:{"all_price":{$gte:90}}
},
{
$sort:{"all_price":-1}//-1表示降序排序,1为升序排列
}
])
2
3
4
5
6
7
8
9
10
11
# 6.5 $limit
对查找到集合中的文档进行数量限制
db.test.aggregate([
{
$project:{trade_no:1,all_price:1}
},
{
$match:{"all_price":{$gte:90}}
},
{
$sort:{"all_price":-1}//-1表示降序排序,1为升序排列
},
{
$limit:1//只返回一条数据
}
])
2
3
4
5
6
7
8
9
10
11
12
13
14
# 6.6 $skip
对查找到的集合中的文档进行一定的跳过忽略
db.test.aggregate([
{
$project:{trade_no:1,all_price:1}
},
{
$match:{"all_price":{$gte:90}}
},
{
$sort:{"all_price":-1}//-1表示降序排序,1为升序排列
},
{
$skip:1//跳过第一条数据,也就是说拿到的数据库中的文档默认是从第二条数据开始的
}
])
2
3
4
5
6
7
8
9
10
11
12
13
14
# 6.7 $lookup
用于进行有关联集合的查找
//单表关联
db.test.aggregate([
{
$lookup:{//下面的写法左边为固定写法
from:"test2",//从哪个关联的集合中查找
localField:"order_id",//该集合中的关联项,名字只要相互对应就可以了
foreignField:"order_id",//关联集合的关联项
as:"items"//自定义的属性
/*
在关联集合中找到的文档会在返回结果的文档中的items属性中存在(作为一个自定义新增的属性),该 值为一个数组,查找到的关联集合中的文档为一个个对象成员
*/
}
}
])
2
3
4
5
6
7
8
9
10
11
12
13
14
//多表关联
db.test.aggregate([
{
$lookup:{
from:"test2",
localField:"order_id",
foreignField:"order_id",
as:"items"
}
},
{
$lookup:{
from:"test3",
localField:"order_id2",
foreignField:"order_id2",
as:"items2"
}
}
])
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 7.Mongoose
# 7.1 下载安装Mongoose
npm i mongoose --save
# 7.2 在项目中引入Mongoose
//导入mongoose
var mongoose=require("mongoose");
//链接mongosedb数据库
mongoose.connect("mongodb://数据库的ip地址:端口号/数据库名",{userNewUrlParser:true});
//如果端口号是默认端口号(27017)则可以省略不写
//断开数据库链接(一般不需要调用)
//mongodb数据库,一般情况下,只需要连接一次,连接一次后除非项目停止服务器关闭,否则连接一般不会断开
mongoose.disconnect();
/*
监听mongodb数据库的连接状态:在mongoose对象中,有一个connection属性,该对象表示的就是数据库连接, 通过监视该对象的状态,可以来监听数据库的连接与断开
*/
//数据库连接成功的事件
mongoose.connection.once("open",function(){});
mongoose.connection.once("close",function(){});
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 7.3 创建模型
//将mogoose.Schema赋值给一个变量
var Sechema=mongoose.Schema;
//创建Schema(模式)对象
var blogSchema = new Schema({//限制属性值
title: String,
author: String,
body: String,
comments: [{ body: String, date: Date }],
date: { type: Date, default: Date.now },//可以有默认值,用默认值时是这种写法
hidden: Boolean,
meta: {
votes: Number,
favs: Number
},
authod_id:{
type:Schema.Types.ObjectId
//类型是一个ObjectId,在创建实例模型的时候可以直接传输ID字符串,会自动转换为ObjectId
}
});
var blogModel=mongoose.model("blog",blogSchema);//默认会在数据库中建立一个复数形式的blog集合
//如果想要指定集合名字,可以传入第三个字符串参数,该参数的就是创建的集合名字
blogMode.create({
title:"我的博客",
author:"Coloring"//假设只用填这两个
},function(err){
if(!err){
console.log("插入成功");
}
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
另一种写法
//另一种方式
const mongoose=require("mongoose");
//连接mongodb服务器
//通过这种方式返回一个对象
const db=mongoose.createConnection(
"mongodb://localhost:27017/数据库名",//有就会直接连接,没有就会在数据库创建并连接
{userNewUrlParser:true}
);
//用原生ES6的Promise取代mongoose自实现的Promise
mongoose.Promise=global.Promise;
//注意:在使用数据库之前,需要使用Schema设置每个字段的数据类型
//将mogoose.Schema赋值给一个变量
const Sechema=mongoose.Schema;
//创建Schema(模式)对象
const blogSchema = new Schema({//限制属性值
title: String,
author: String,
body: String,
comments: [{ body: String, date: Date }],
date: { type: Date, default: Date.now },//可以有默认值,用默认值时是这种写法
hidden: Boolean,
meta: {
votes: Number,
favs: Number
}
});
const blogModel=mongoose.model("blog",blogSchema);
/*
默认会在数据库中建立一个复数形式的blog集合
如果想要指定集合名字,可以传入第三个字符串参数,该参数的就是创建的集合名字
*/
const d1=new blogModel({
title:"我的博客",
author:"Coloring"//假设只用填这两个
});
d1.save().then(res=>{//因为在之前用mongoose.Promise=global.Promise;所以现在可以用ES6的语法
console.log(res);
}).catch(err=>{
console.log(err);
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# 7.3.1 mongoose修辞符
**trim:**内置修饰符,用于将传入的String类型的数据进行去除两端的空格
**set:**自定义修辞符函数,用于用户自己定义传入后的参数的变化
const blogSchema = new Schema({//限制属性值
name:{
type:String,
trim:true,
ser(value){//自定义修辞符,将传入name属性进行自定义的改变,第一个形参就是对应的属性
return value;
}
}
});
2
3
4
5
6
7
8
9
# 7.3.2 mongoose校验参数
内置校验参数
- **type:**指定类型
- **require:**表示这个数据必须传入
- **max:**用于Number类型数据的最大值
- **min:**用于Number类型数据的最小值
- **maxlength:**字符串最大值,注意的是这个参数和下面四个参数都是用于String类型的
- **minlength:**字符串最小值
- **enum:**枚举类型,要求数据必须为枚举值,如
enum:['0','1','2'] - **match:**增加的数据必须符合match(正则)的规则
const blogSchema = new Schema({//限制属性值 name:{ type:String, require:true, maxlength:10, minlength:1, enum:["zhangsan","lisi"],//传入的数据必须为张三或者李四, match:/^zhangsan$/i //math的值应该是一个正则表达式 }, age:{ type:Number, require:true, max:100, min:0, } });1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16自定义校验参数
**validate:**该值应该赋值为一个函数,第一个形参就是要校验的属性
const blogSchema = new Schema({//限制属性值 name:{ type:String, validate:function(val){ return val.length>10;//如果返回false代表验证失败 } } });1
2
3
4
5
6
7
8
# 7.3.3 mongoose设置索引
- **index:**设置普通索引,设置后就可以使用
Model.getIndexes依靠设置的索引查找到对应的文档 - **unique:**设置唯一索引,唯一索引的值在数据库中只能出现一次,不能够像普通索引一样可以是相同的值
const blogSchema = new Schema({//限制属性值
name:{
type:String,
index:true
},
age:{
type:Number,
unique:true
}
});
2
3
4
5
6
7
8
9
10
# 7.4 Model的方法
# 7.4.1 创建文档
使用Model.create()用来创建一个或多个文档并添加到数据库中
参数:
- doc(s),可以是一个文档对象,也可以是一个包含文档对象的数组
- callback,当操作完成以后调用的回调函数
Candy.create({ type: 'jelly bean' }, { type: 'snickers' }, function (err, jellybean, snickers) {
if (err) // ...
});
var array = [{ type: 'jelly bean' }, { type: 'snickers' }];
Candy.create(array, function (err, candies) {
if (err) // ...
var jellybean = candies[0];//第二个参数是插入的文档
var snickers = candies[1];
// ...
});
// 可以不写回调函数而写Promise的形式
var promise = Candy.create({ type: 'jawbreaker' });
promise.then(function (jawbreaker) {
// ...
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 7.4.2 查询文档
Model.find(conditions,[projection],[options],[callback])查询所有符合条件的文档,结果总会返回一个数组
参数:
condions,查询的条件
**注:**如果传入的是一个空对象会返回所有的文档
projection,投影,拿到需要获取到的字段,该参数有两种写法
- **对象写法,**同使用原始的mongodb查询数据一样,1代表显示,0代表不显示,默认显示_id,如
{name:1, _id:0} - **字符串写法,**用空格当分割符,如果写了就代表要投影出该属性,默认显示_id,如果不想显示在前面添加
-号,如"name - _id"
- **对象写法,**同使用原始的mongodb查询数据一样,1代表显示,0代表不显示,默认显示_id,如
options,查询选项,如skip,limit等填写在该对象中,如
{skip:3,limit:1}callback,回调函数,查询结果会通过回调函数返回,回调函数必须传,如果不传回调函数,该查询方法不会进行,该回调函数的第一个参数是错误参数,第二个参数是查询到的文档
所以增删改查方法都会返回一个Promise对象,所以可以用
then()来接收后续代码
Model.findById(id(string),[projection],[options],[callback])根据文档的ID查询文档,返回一个对象
**注:**该函数通过传入文档的字符串id进行查询
Model.findOne(conditions,[projection],[options],[callback])查询所有符合条件的第一个文档,总会返回一个具体的文档对象
注意:
- 通过find()等查询到的结果返回的对象就是Document文档对象,Document就是Model的实例
- 在mongoose中不能直接通过
_id:"具体ID字符串"的进行查找文档,必须使用对应查找ID的API或者使用mongoose.Types.ObjectId("ObjectId字符串")封装成一个ObjectId对象来查找
# 7.4.3 修改文档
Model.update(conditions,doc,[options],[callback])用来修改一个或多个文档
参数:
- condions,查询条件
- doc,修改后的对象
- options,配置参数
- callback,回调函数
Model.updateOne(conditions,doc,[options],[callback])
Model.updateMany(conditions,doc,[options],[callback])
Model.replaceOne(conditions,doc,[options],[callback]),该函数不用传入
$set来修改指定值,只需要传入要修改的对象就可以了Model.findByIdAndUpdate(_id,doc,[options],[callback]),根据ID进行查找和更新
# 7.4.4 删除文档
- Model.remove(conditions,[callback]),默认删除多个文档,如果只想删除一个把conditons中的single设置为true
- Model.deleteOne(conditions,[callback])
- Model.deleteMany(conditions,[callback])
- Model.findByIdAndRemove(id,[callback])
# 7.4.5 计算文档总数
Model.count(conditions,[callbcak])能计算查询到的文档总数,该值在callback的第二个参数中
Candy.count({},function(err,count){
console.log(count);
})
2
3
# 7.4.6 moogoose聚合管道
moogoose中的聚合管道与原生的mongodb中的聚合管道用法类似,只需要用Model.aggregate()内部传入同样的管道操作符即可
Candy.aggregate([
{
$lookup:{//下面的写法左边为固定写法
from:"test2",//从哪个关联的集合中查找
localField:"order_id",//该集合中的关联项,名字只要相互对应就可以了
foreignField:"order_id",//关联集合的关联项
as:"items"//自定义的属性
/*
在关联集合中找到的文档会在返回结果的文档中的items属性中存在(作为一个自定义新增的属性),该 值为一个数组,查找到的关联集合中的文档为一个个对象成员
*/
}
},
{
$lookup:{
from:"test3",
localField:"order_id2",
foreignField:"order_id2",
as:"items2"
}
},
{
$match:{_id:mongoose.Types.ObjectId("5d11b5e3ec794933d42f67e8")}
//在mongoose中使用mongoose.Types.ObjectId("ObjectId字符串")来查找Objectid
}
],function(err,docs){
if(err){
console.log(err);
return;
}
console.log(JSON.stringfy(docs));
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 7.4.7 文档关联查询
mongoose大于3.2以上的版本推荐使用mongodb中的聚合管道的$lookup进行管理查询
mongoose自己实现了一个强大的关联查询的方法
populate()实现表的关联查询注意:
- 使用populate()方法需要引用所有用的的Model到同一个文件中
- 该方法常和
exec()方法一起使用,exec()方法相当于then()方法,是前面所有方法执行完后才会执行,传入一个回调函数,第一个参数是错误对象,第二个参数是查询到的文档数组对象 - 该方法使用时需要在Schema中的要被关联文档替代的属性设置
{type: Schema.Types.ObjectId, ref: '要关联的集合'}
Model中的用法:
Model.populate(path, [select], [model], [match], [options])**path:**类型为
String或ObjectString类型的时, 指定要填充的关联字段,要填充多个关联字段可以以空格分隔。Object类型的时,就是把 populate 的参数封装到一个对象里。当然也可以是个数组,用于多个文档的关联查找
**select:**类型为
Object或String,可选,指定填充document文档中的哪些字段Object类型的时,格式如:{name: 1, _id: 0},为0表示不填充,为1时表示填充String类型的时,格式如:"name -_id",用空格分隔字段,在字段名前加上-表示不填充
**注:**详细语法介绍 query-select (opens new window)
**model:**类型为
Model,可选,指定关联字段的model(所以如果没有在Schema中指定ref也是能进行操作的),如果没有指定就会使用Schema的ref**match:**类型为
Object,可选,指定附加的查询条件**options:**类型为
Object,可选,指定附加的其他查询选项,如排序以及条数限制等等
var mongoose = require('mongoose'); var Schema = mongoose.Schema; var UserSchema = new Schema({ name : { type: String, unique: true }, posts : [{ type: Schema.Types.ObjectId, ref: 'Post' }]//关联多个帖子用数组,固定写法 /* ref是用于指定关联的数据库,在使用populate方法的时候只需要传入要替换的字段,就能通过该字段属性在 Schema中的ref指定的关联文档进行查找,一般该属性传入的是一个ObjectId,所以类型是ObjectId,通过 这种方式就可以通过查找传入的ObjectId的字符串查找到对应的关联文档,查找到的文档会直接覆盖掉这个 属性原来的值,这样达到查找关联的效果 */ }); var User = mongoose.model('User', UserSchema); var PostSchema = new Schema({ poster : { type: Schema.Types.ObjectId, ref: 'User' }, comments : [{ type: Schema.Types.ObjectId, ref: 'Comment' }], title : String, content : String }); var Post = mongoose.model('Post', PostSchema); var CommentSchema = new Schema({ post : { type: Schema.Types.ObjectId, ref: "Post" }, commenter : { type: Schema.Types.ObjectId, ref: 'User' }, content : String }); var Comment = mongoose.model('Comment', CommentSchema);1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26//传入数据 var user = User.findOne({name:"张三"}); var post1 = Post.findOne({title:"第一篇帖子"}); var post2 = Post.findOne({title:"第二篇帖子"}); user.posts=[post1,post2];//设置一对多的关联 //设置关联,可以直接把整个对象关联,会直接将这个对象的ObjectId存入,也可以直接[post1_id,post2_id] post1.poster=user; //设置一对一的关联,因为上面设置的时候不是一个数组,所以只能设置一个,可以直接user_id1
2
3
4
5
6
7
8//填充所有 users 的 posts User.find() .populate('posts', 'title', null, {sort: { title: -1 }}) .exec(function(err, docs) { console.log(docs[0].posts[0].title); // post-by-aikin }); //填充 user 'luajin'的 posts User.findOne({name: 'luajin'}) .populate({path: 'posts', select: { title: 1 }, options: {sort: { title: -1 }}}) .exec(function(err, doc) { console.log(doc.posts[0].title); // post-by-luajin }); //这里的 populate 方法传入的参数形式不同,其实实现的功能是一样的,只是表示形式不一样。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15Post.findOne({title: 'post-by-aikin'}) .populate('poster comments', '-_id') .exec(function(err, doc) { console.log(doc.poster.name); // aikin console.log(doc.poster._id); // undefined console.log(doc.comments[0].content); // comment-by-luna console.log(doc.comments[0]._id); // undefined }); Post.findOne({title: 'post-by-aikin'}) .populate({path: 'poster comments', select: '-_id'}) .exec(function(err, doc) { console.log(doc.poster.name); // aikin console.log(doc.poster._id); // undefined console.log(doc.comments[0].content); // comment-by-luna console.log(doc.comments[0]._id); // undefined }); //上两种填充的方式实现的功能是一样的。就是给 populate 方法的参数不同。 //这里要注意,当两个关联的字段同时在一个 path 里面时,select 必须是 document(s)具有的相同字段。 //如果想要给单个关联的字段指定 select,可以传入数组的参数。如下: Post.findOne({title: 'post-by-aikin'}) .populate(['poster', 'comments']) .exec(function(err, doc) { console.log(doc.poster.name); // aikin console.log(doc.comments[0].content); // comment-by-luna }); Post.findOne({title: 'post-by-aikin'}) .populate([ {path:'poster', select: '-_id'}, {path:'comments', select: '-content'} ]) .exec(function(err, doc) { console.log(doc.poster.name); // aikin console.log(doc.poster._id); // undefined console.log(doc.comments[0]._id); // 会打印出对应的 comment id console.log(doc.comments[0].content); // undefined });1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
# 7.4.7.1 文档关联高级用法
使用populate()进行文档关联的时候也可以像聚合管道一样进行高级关联
**比如:**被关联的类别也可以拿到关联它的关联项,实现一对多的用法
const Post=mongoose.model("Post",new mongoose.Schema({
title:{
type:String
},
body:{
type:String
},
categories:[{type:mongoose.SchemaTypes.ObjectId,ref:"Category"}]
}))
const CategorySchema=new mongoose.Schema({
name:{type:String}
},{
toJSON:{virtuals:true}//调用toJSON方法时默认会把虚拟字段加上,与express的res.send()配合
})
//想要获取关联词类别的的posts,需要定义一个虚拟字段
//设置虚拟字段
CategorySchema.virtul("posts",{//posts是设置的虚拟的属性
ref:"Post",//要关联的集合
localField:"_id",//自身要关联的字段
foreignField:"categories",//对方集合要关联的字段
justOne:false//表示查出来的数据是否只有一条,如果是false返回数组,如果是true返回对象
})
//要先设置虚拟字段再创建模型
const Catagory=mongoose.model("Category",CategorySchema);
Category.find().populate("posts").then((err,docs)=>{
console.log(docs);//注意,因为是虚拟字段,在mongoose的机制里默认不会显示,除非加了上面的参数
console.log(docs[0].posts);//但是如果真实的获取会获取到它的信息
console.log(JSON.stringify(posts));
/*
因为设置了参数
{
toJSON:{virtuals:true}
}
所以调用JSON.stringify会有虚拟字段,否则不会有虚拟字段
*/
//也可以使用一种更好的方法
docs=docs.lean();//表示将对象转换为纯JSON对象,这样就可以得到虚拟字段中的数据了
console.log(docs);
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# 7.4.8 扩展Model方法
静态方法:通过对Schema的statics属性上添加静态方法
UserSchema.statics.findById=function(uid,cb){ this.find({"_id":uid},function(err,docs){ cb(err,docs); }) }1
2
3
4
5实例方法:通过对Schema的methods属性上添加实例方法
UserSchema.methods.print=function(){ console.log("这是一个实例方法"); console.log(this); }1
2
3
4
**注意:**不能按照常规类的写法来写,不然会报错
# 7.5 Document方法
Document和集合中的文档一一对应,Document是Model的实例,通过Model查询到结果都是Document
**Document.save([options].[fn]),**该方法用于将文档保存到数据库
const candy=new Candy({ name:"candy", age:18 });//只这样是不会保存到数据库的,还需要使用save()方法 candy.save(function(err){ if(!err){ conosole.log("保存成功"); } })1
2
3
4
5
6
7
8
9**Document.update(update,[options],[callback]),**该方法用于修改对象,不过不用传入查找方式,直接修改调用该方法的文档
Candy.findOne({},function(err,doc){ if(!err){ doc.update({$set:{age:20}},function(err){ console.log("修改成功"); }); } })1
2
3
4
5
6
7**Document.remove([callback]),**该方法用于删除当前文档对象
Document.get(name),该方法用于获取文档中的指定属性,等同于直接
文档.属性Document.set(name.value),该方法用于设置文档中的指定属性值,等同于直接
文档.属性=值**注意:**使用该方法数据库中的值也不会改变,因为还没有调用save()方法
Document.id,用于获取文档的
_id(当然直接使用Document._id也是可以获取到的)Document.toObject(),该方法可以将一个Document对象转变为普通的对象,转变后不能再使用Document对象的方法,但是其属性能被
delete 属性名删除,而且也不能使用Document.id获取_id,但是可以使用Document._id来获取
# 7.6 模块化导入数据库
先定义一个模板用来连接mongodb数据库
//connect.js const mongoose=require("mongoose"); mongoose.connect("mongodb://数据库的ip地址:端口号/数据库名",{userNewUrlParser:true}); //如果端口号是默认端口号(27017)则可以省略不写 //可以用作测试 mongoose.connection.once("open",function(){ console.log("数据库链接成功"); })1
2
3
4
5
6
7
8定义模板创建需要的模型
//student.js const mongoose=require("mongoose"); const Schema=mongoose.Schema; let Student=new Schema({ name:String, age:Number, gender:{ type:String, default:"female" }, address:String }) const StudentModel=mongoose.model("student",Student); module.exports=StudentModel;//导出模型对象1
2
3
4
5
6
7
8
9
10
11
12
13
14使用模型
require("./connect.js");//因为不用导出数据,所以可以不赋值 const Student=require("./student.js"); //测试用 Student.find({},function(err,docs){ if(!err){ console.log(docs); } })1
2
3
4
5
6
7
8
9
- 01
- 2023/07/17 13:57:35
- 02
- 2023/07/17 10:12:59
- 03
- 2023/07/17 09:24:52